CLINQ VoIP Backend

After we at CLINQ decided on a product pivot towards the softphone market, we wanted to see if our core idea (moving the client-side SIP stack to the server-side cloud infrastructure) could be used to build the new strategy. I developed the plan for the proof of concept with my team. To do this, I used the approach of a "walking skeleton" (vertical prototype).
CLINQ has already pivoted a time or two. But now it should move away from the integrated telephone system. If you want to know the reasons for this, feel free to write. That would blow this up ;)
CLINQ: The best softphone
So, we have a new strategy. The associated vision was "CLINQ: The best softphone on the market". We divided the vision into phases so that we could derive a plan and individual missions from it. The first phase (still today) consists of rethinking everything fundamental about a softphone. According to our user surveys, the basic properties or features of a softphone are as follows (unordered):
Incoming and outgoing calls (HA! Would you have guessed?)
Forwarding,
toggling
DTMF (key tones for navigation in voice dialog systems)
contacts
Selection of audio devices
Call list.
So, in order to build the "best softphone" according to the vision, we jumped on all these features especially in the UX and rethought them. Do you know what was the first thing everyone from the UX gave as feedback?
This:
Setting up a softphone with all this technical stuff around SIP is a disaster.
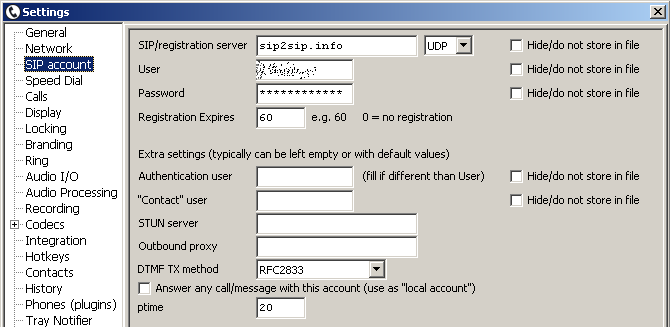
Now this is where my team came in.
In order for the user of CLINQ to really get a simple softphone, everything that can/must be set up for SIP should go into the backend. This would save most users a trip to the admins or even make the work for admins much easier.
Our idea was to put the SIP client (or the SIP logic on the client side) into the backend, so that in the actual CLINQ client as little as possible technical foo has to take place to be able to establish an audio stream / a phone call. Therefore we decided to use the following solution:
VoIP Provider <-> CLINQ Backend <-> CLINQ Frontend
Advantages
All technical requirements to set up a phone call are in our hands and the user does not need to worry about anything (User centered)
The client becomes technically easier for development: Instead of SIP signaling we now use REST calls + WebRTC (Developer experience)
Easy sync between multiple clients: mobile & desktop (User centered)
In the future more USP features, like smooth handover to other clients, audio recording, TTS & STT, etc... (Pays for future vision derivations)
How we reduced the risk
Since the solution idea is the biggest risk, we had to shed light on it quickly. Of course, there were already a lot of ideas in the heads, but little to nothing tangible.
In a Sprint Zero, we conceptually mirrored our ideas and quickly included initial questions as so-called spikes (proof of concept) in the backlog.
Among them were such questions as:
"Is there a timing issue when we transcode between SIP and WebRTC".
"Can we implement a simple SIP stack in Java at all? (KISS)"
"How or with what do we do audio processing?"
Within the sprint we were able to clarify corresponding questions so far and an architecture vision was developed by us:
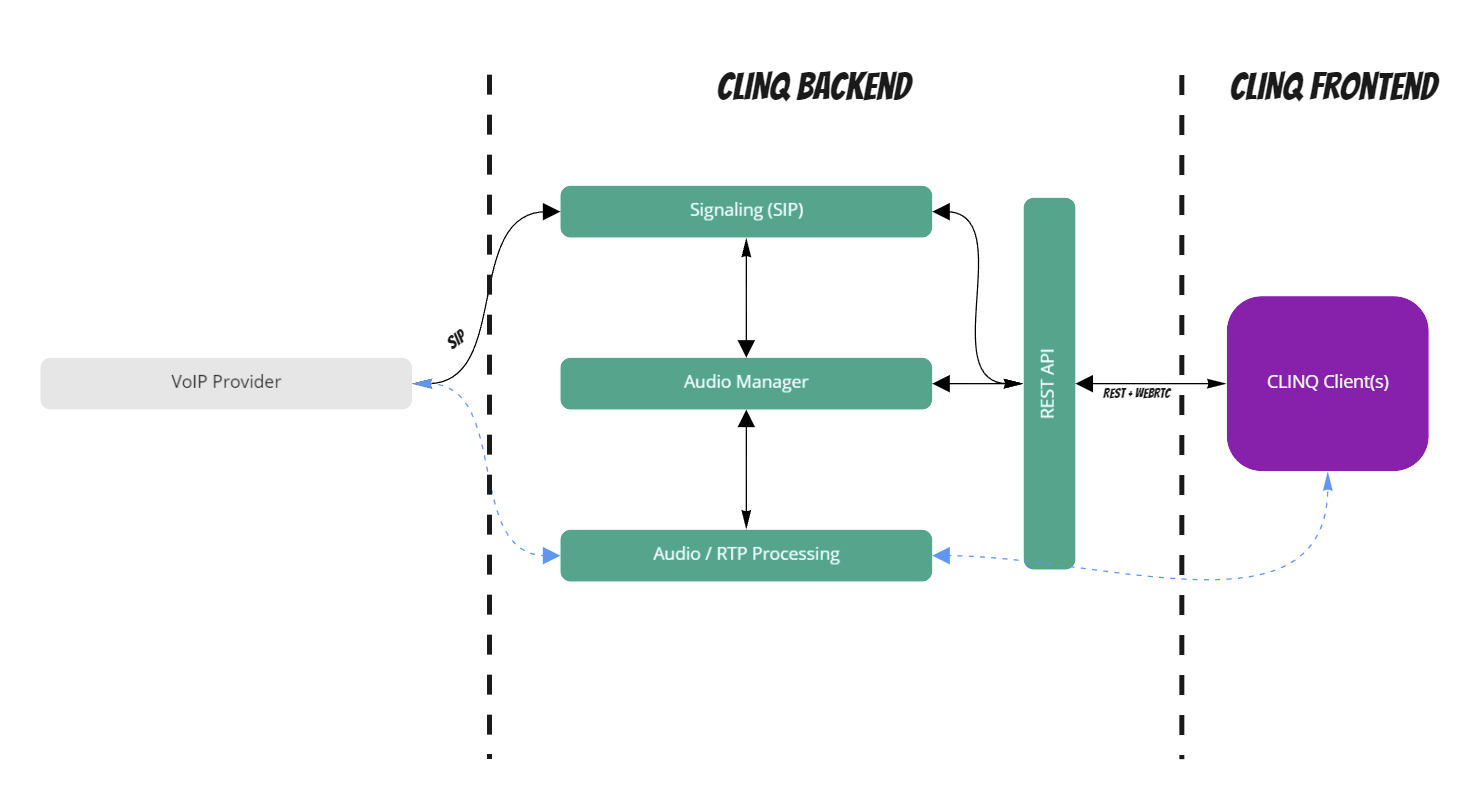 So in the next sprint we had to prove the feasibility of the architecture vision. The assumption that we could complete such complex processes as setting up and connecting audio streams, including connection to external VoIP providers, in a two week sprint was very naive :D
So in the next sprint we had to prove the feasibility of the architecture vision. The assumption that we could complete such complex processes as setting up and connecting audio streams, including connection to external VoIP providers, in a two week sprint was very naive :D
Walking Skeleton
So for the next sprint(s), the goal was to test the architectural vision for feasibility. For this I used the Walking Skeleton concept and worked out the first functional implementations with the team and the user story mapping.
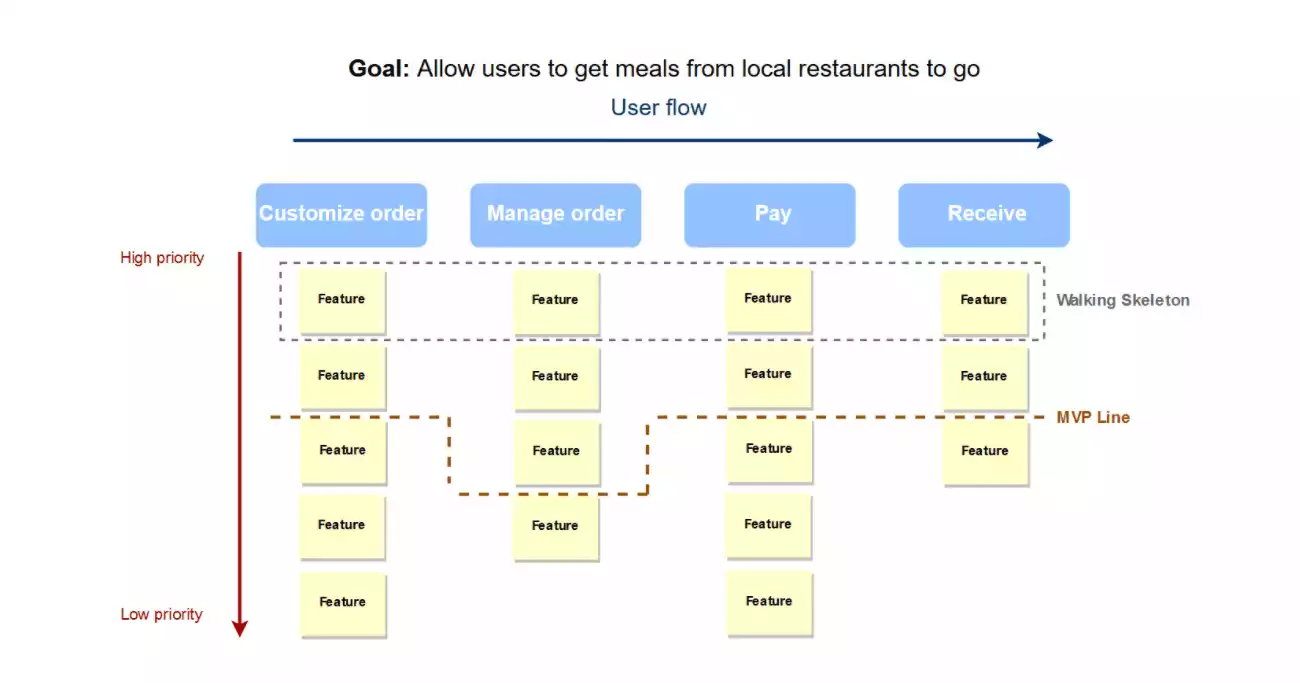 Conclusion
Conclusion
We managed to empirically minimize the biggest risk for the product and at the same time lay the foundation for today's CLINQ. When I left sipgate at my own request, we had a solid VoIP backend through which all users make their calls today. In addition, thanks to observability, we know exactly when and where problems occur.
Credits: